なぜテストを増やしてもソフトウェア品質は向上しないのか

「テストカバレッジ100%」は理想か、それとも幻想か?
ソフトウェアテストに携わったことのある方は、「テストカバレッジは100%を目指すべきだ」といった言葉を耳にした経験があるかもしれません。
すべてのコードが網羅的にテストされ、バグや欠陥が一切ないという、まるで完璧ともいえる状態です。しかし、本当にテストカバレッジが100%に達したからといって、ソフトウェアの品質は保証されるのでしょうか。
残念ながら、答えはNOです。
この記事では「なぜテストを増やしても品質が向上するとは限らないのか」、そして「完璧なカバレッジを目指すことが逆効果になる理由」を解説します。さらに、効率的に品質を高める方法についてもご紹介します。その前に、まずは基本を確認しておきましょう。
目次
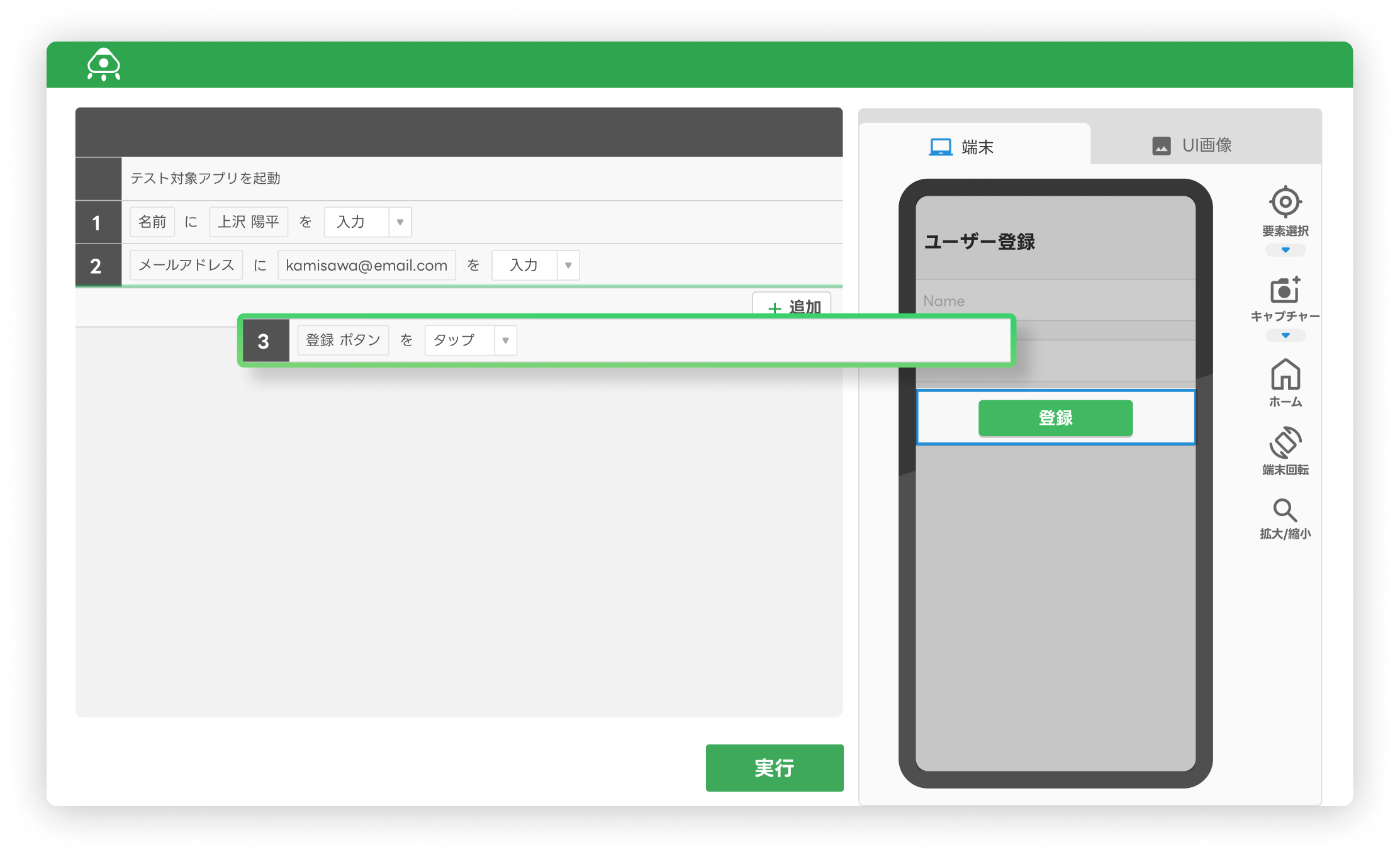
テストカバレッジとは?
テストカバレッジとは、コード全体のうち、どのくらいの割合がテストされているかを示す指標です。
テストカバレッジにはいくつかの測定方法があり、例えばステートメントカバレッジ(C0)、デシジョンカバレッジ(C1)、コンディションカバレッジ(C2)などが代表的です。こうした指標は一見すると便利に思えますが、測定しているのはあくまで「コードがどれだけテストされたか」という量的な情報に過ぎません。
※テストカバレッジの詳細についてはこちらをご参照ください。
つまり、これらは「テストの質」や「実際にバグを検出できているか」といった有効性までは評価できないという点に注意が必要です。
言い換えれば、テストカバレッジが100%だったとしても、それが高品質なソフトウェアを意味するとは限らないのです。
なぜ開発チームはテストカバレッジを重視するのか?
それでも多くの開発チームがテストカバレッジを重視する理由は、品質を定量的に測るわかりやすい指標だからです。背景には以下のような事情があります。
1. バグは早期に見つけたほうが修正コストが安い
テストカバレッジが高いということは、それだけ多くのコードが一度は実行されているということを示しており、バグを早期に発見できる可能性が高まります。
これにより、null参照エラーや例外処理の漏れなど、ユーザーに影響が出る前に問題を防止することができます。
2. 安心してコードを変更できる
現代の開発では、機能追加やリファクタリングが頻繁に発生します。こうした環境下では、自動テストによってリグレッション(デグレ)を検出できることが、安心して変更を加えるうえで重要です。
特に大規模なコードベースでは、すべてを手動で確認するのは現実的ではなく、自動テストに頼る必要があります。
3. 一部の業界では法的な要件になることもある
医療、金融、航空といった業界では、品質・信頼性・セキュリティに関して厳格な基準が求められます。このような分野では、「すべての機能がテストされている」という証拠を法的に提出しなければならないケースもあります。
例えば、米国のFDA(食品医薬品局)は、医療機器に使われるソフトウェアに対して、徹底的なテストを承認の条件として義務づけています。
4. CI/CD環境における品質ゲートとして機能する
現在のソフトウェア開発では、CI/CDによる自動テストおよび自動デプロイの仕組みが広く普及しています。この中で、テストされていないコードが本番環境にリリースされるのを防ぐための「品質ゲート」として、テストカバレッジが活用されることも少なくありません。
つまり、「一定のカバレッジを満たしていないコードは本番環境に進めない」といったルールをパイプラインに組み込むことで、開発の安定性を保つことができるのです。
テストを増やすだけでは逆効果になることも
これまでの話から、テストカバレッジが一定の意味を持つことは明らかです。しかし、100%の達成を目的にしてしまうと、思わぬ弊害を招く可能性があります。
1. 完璧という錯覚に陥る
100%を達成すると「これで問題ない」と思ってしまいがちですが、自動テストでは拾えないバグ、例えばエッジケースやユーザーの操作パターンなどは見逃されることがあります。
カバレッジはあくまでコードベースの網羅率であって、実際の利用状況を反映したものではありません。
2. 意味のないテストが増える
100%に近づけることが目的になってしまうと、実質的に価値のないテストを無理に書くケースが増えてきます。
例えば、次のような定数を返す関数がある場合を考えてみましょう。
function getAppVersion() { return "1.0.0";}この関数が "1.0.0" を返すかどうかを確認するテストを書いても、品質の向上にはまったく貢献しません。ただの「カバレッジを上げるためのテスト」でしかなく、実際の価値はほぼゼロです。
3. 本質的なシナリオが見落とされる
たとえカバレッジが高くても、負荷がかかっている状況や複雑な操作の組み合わせなど、実際のバグの温床となるケースがテストされていないことがあります。数字ばかりを追いかけていては、現実に即した品質は得られません。
つまり、カバレッジを目的化してしまうと、かえって品質向上から遠ざかるリスクがあるのです。
本当に重要なのは「テストの質」
ソフトウェアの品質を適切に評価するには、テストカバレッジだけに頼るのではなく、複数の視点からチェックする必要があります。
以下は、カバレッジと組み合わせて見るべき代表的な指標です。
1. 欠陥密度(バグ密度)
例えば、1万行のコードに50件のバグがあれば、欠陥密度(バグ密度)は「5件/KLOC(千行)」になります。
カバレッジが高くてもこの数値が高ければ、本質的なバグを見逃している可能性があるということです。
2. コードの複雑さ
条件分岐が多い関数や、処理が複雑に入り組んでいる部分は、バグの温床になりやすい場所です。
そのような箇所のカバレッジが低ければ、重大な欠陥が潜んでいるリスクが高まります。
3. コードの変更頻度
何度も変更されているコードは、不安定だったり設計に問題があるサインかもしれません。例えば、ログイン機能が頻繁に書き換えられているなら、そこは重点的にテストをするべき領域です。
4. テストの有効性とユーザー受け入れテスト
実際にバグを検出できているかどうか(=テストの有効性)、そしてソフトウェアがユーザーの期待や要件を満たしているかどうか(=UAT)という視点も、品質評価には欠かせません。
例えば、ライドシェアアプリの基本機能が一通りテストされているにもかかわらず、ユーザーから「目的地を選択するとクラッシュする」といった報告が相次ぐようであれば、そのテストが現実の使用状況を十分に反映していない可能性があります。
これは、テスト内容が実際のユーザー体験と乖離していることを示すサインです。
カバレッジは魔法の数値ではない
数字だけを追いかけても意味はありません。大切なのは、テストの質・意義・現実との整合性です。
実際のユーザーが直面するシナリオ、ビジネスにとって重要な機能、リスクの高い領域、そのような箇所にリソースを集中させてテストすることが、本当に信頼できるソフトウェアを作る鍵となります。
本当に目指すべきゴールとは?
100%のカバレッジを「目的」として追いかけますか?
それとも、品質に焦点を当てた「手段」として、より効率的なテスト戦略を築いていきますか?
テストの本来の目的は、数値を満たすことではなく、ユーザーにとって信頼できるソフトウェアを提供することです。
その原点を忘れず、より本質的なテストのあり方を考えていきましょう。
参考文献
Original article: https://blog.magicpod.com/more-tests-better-quality
補足情報
テストカバレッジの種類とその意味
テストカバレッジと一口に言っても、その測定方法には複数の種類があり、それぞれ異なる観点からコードの網羅性を評価します。
ここでは、代表的な4つのカバレッジ指標についてご紹介します。
- C0:ステートメントカバレッジ(命令網羅)
- C1:デシジョンカバレッジ(分岐網羅)
- C2:コンディションカバレッジ(条件網羅)
- MCC:マルチコンディションカバレッジ(複合条件網羅)
C0:ステートメントカバレッジ(命令網羅)
ステートメントカバレッジ(命令網羅)とは、すべての命令文が1回以上実行されるようにテストする指標です。
以下のようなコードを例にすると、
(x, y) = (1, 11) のような1ケースだけで、すべての命令文が実行され、ステートメントカバレッジは100%に達します。
public static void sample(int x,int y){
if(x>0 && x<50){
if(y>10){
System.out.println("Hello World");
}
}
}
このカバレッジは、テストケースを少なく抑えられるため、テスト作成の手間を減らすことができますが、条件や分岐の網羅性は考慮されないため、見逃されるバグも少なくありません。
C1:デシジョンカバレッジ(分岐網羅)
デシジョンカバレッジ(分岐網羅)とは、すべての分岐(if文など)が少なくとも1回はtrue/false両方のパスを通るようにテストする指標です。
以下のようなコードを例にすると、
2つの条件式に対してtrue/falseを網羅するために、(x, y) = (1, 11), (1, 9), (-1, 11) など最低3ケースが必要になります。
public static void sample(int x,int y){
if(x>0 && x<50){
if(y>10){
System.out.println("Hello World");
}
デシジョンカバレッジが100%であれば、ステートメントカバレッジ(C0)も自動的に100%になります。ただし、C0に比べてテスト作成の負荷はやや高くなります。
C2:コンディションカバレッジ(条件網羅)
コンディションカバレッジ(条件網羅)とは、複数の条件が含まれる式において、それぞれの条件がtrue/falseの両方を1回以上通るようにテストする指標です。
先ほどと同じコードを使用して解説すると、
この場合、x > 0, x < 50, y > 10の各条件について、それぞれtrue/falseのパターンをすべてカバーする必要があります。
例えば、(x, y) = (1, 11), (1, 9), (51, 11), (-1, 11) のような最低4ケースが必要です。
public static void sample(int x,int y){
if(x>0 && x<50){
if(y>10){
System.out.println("Hello World");
}
}
}
なお、コンディションカバレッジが100%になっていても、必ずしもステートメントカバレッジ(C0)やデシジョンカバレッジ(C1)が100%になるとは限りません。
その理由を、以下のコードで検証してみましょう。
(x, y) = (1, -1), (-1, 1) のような2ケースで、x > 0 と y < 50 がそれぞれtrue/falseになるようテストすれば、コンディションカバレッジとしては100%になります。
しかし、実際にはどちらも if 条件を満たさないため、System.out.println() の実行に至らず、デシジョンカバレッジは50%にとどまります。
public static void sample(int x,int y){
if(x>0 && y<50){
System.out.println("Hello World");
}
}MCC:マルチコンディションカバレッジ(複合条件網羅)
条件式に含まれるすべての条件の真偽の組み合わせを網羅する指標です。最も網羅性が高い一方で、テストケース数が急激に増えるという特徴があります。
以下のコードを使用して解説すると、
この条件式では、x > 0 と y < 50 の2つの条件があり、true/falseのすべての組み合わせ(2条件で2²=4通り)を網羅する必要があります。
つまり、以下の4ケースが必要になります:
- (1,49)
- (1,51)
- (-1,49)
- (-1,51)
public static void sample(int x,int y){
if(x>0 && y<50){
System.out.println("Hello World");
}
}
マルチコンディションカバレッジは非常に高い網羅性を持ちますが、条件の数が増えるごとにテストケース数が指数的に増加するため、実用上は対象やリスクに応じて適用範囲を限定するのが現実的です。
適切なカバレッジ指標の選び方
どのカバレッジ指標を使うべきかは、ソフトウェアの特性や品質要件によって異なります。
例えば、ビジネスロジック中心の業務アプリであればC1やC2で十分な場合もありますが、安全性や正確性が求められる領域(医療・金融・航空など)ではMCCのような厳密な指標が求められることもあります。
重要なのは、「カバレッジを高めること」ではなく、「高める理由と対象を明確にすること」です。
数値に振り回されず、リスクや目的に応じたテスト設計を心がけることが、信頼できる品質につながります。
欠陥密度(バグ密度)の計算方法
ソフトウェアの品質を定量的に把握するうえで、欠陥密度(Defect Density)は有効な指標のひとつです。これは、ある開発規模に対してどれだけのバグが検出されたかを示すもので、テストの有効性やコードの安定性を評価する材料になります。
欠陥密度の基本的な計算式
欠陥密度は、以下の式で求められます。
欠陥密度 = 検出されたバグの数 ÷ 開発規模
ここでの「開発規模」には、以下のような指標を使うことが一般的です。
- LOC(Lines of Code):ソースコードの行数
- KLOC(Kilo Lines of Code):1,000行あたりの行数単位
- FP(Function Point):ソフトウェアの機能的な規模を表す単位
例えば、10,000行のコードに50件のバグが見つかった場合、KLOC単位で表すと欠陥密度は「5件/KLOC」となります。
なぜKLOCやFPで割るのか?
開発規模が大きければバグの絶対数も増えやすくなるため、バグの数を規模で割ることで比較可能な密度に正規化することができます。プロジェクトごとの規模差を吸収できるため、横断的な品質評価にも適しています。
欠陥密度とテスト密度との違い
なお、テスト件数を同様に開発規模で割った「テスト密度(Test Density)」という指標もあります。これは「どれだけのテストが実施されているか」を示すもので、欠陥密度と組み合わせることで、どの程度テストされていて、実際にどれだけバグが検出されているかを相対的に評価することが可能になります。